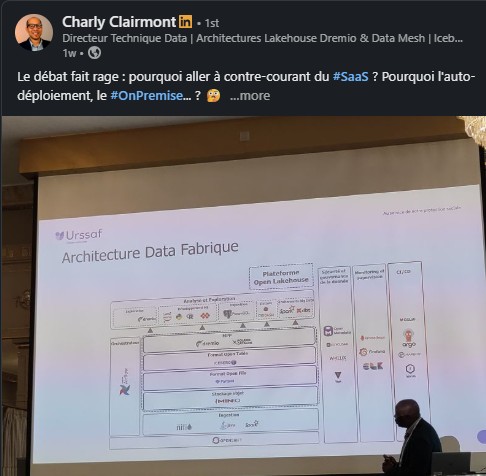
|
dbt-core ! Et après ? un ETL ? Quel futur ETL ?

L’achat de DBT par Fivetran a tellement posé de questions qu’il convient de rappeler que DBT est une solution parmi d’autres. D’abord nos vieilles plateformes font toujours une bonne soupe ! Je veux parler ici de Qlik Talend ou les Informatica et consorts.
Et de rappeler encore que si le marché se consolide, que
nous voilà arrivés à l’apogée de la Modern Data Stack
, que nombre de propositions nouvelles existent. Par exemple,
Apache Flink™
connaît une vraie remise en valeur, vous pouvez par exemple l’employer avec un
Apache Hop™
: ça le fait !
En France nous avons
Kestra
qui à sorti et sa version 1.0 et son LTS ! Certes, c’est un orchestrateur ! Il présente toutes les caractéristiques utiles à l’élaboration de vos flux ETL et de leur suivi. Qui on oubli ? Et bien, et bien nous pouvons parler de
Starlake.ai
, un français encore : une approche déclarative tout comme Kestra. C’est plus facile pour les LLM ! Ces derniers peuvent mieux vous aider que s’il s’agissait de glisser-déposer. Là aussi qu’à celà ne tienne : ça changera !
Et le changement c’est maintenant (elle est facile n’est-ce pas ?) ! On embauche moins de jeunes… Sous prétexte que l’IA va les remplacer… Et nous sommes dans un moment avec beaucoup d’attentisme… Qui a aidé les organisations à embrasser le web, l’ecommerce, le mobile, les réseaux sociaux ? Qui ? Ceux qui savaient l’utiliser ? Ceux qui s’y sont mis avant les autres !
Avant que l’IA ne porte ces fruits, il va falloir que l’organisation tout entière l’embrasse
, comme le mail… Et s’il l’on doit gérer et parler aux données, les mettre en qualité ! Qui va faire ça l’IA, toute seule… Il faut lui donner les instructions, lui dire, lui redire, reformuler… Améliorer la réponse plus d’une fois pour être satisfait avec un résultat qui nous convient…
Tout ceci pour parler de cadre de traitement de données comme
Daft
,
Pola-RS
ou de
Coco-Index
! Coco-Index est nouveau, ce qui est intéressant c’est qu’il sait traiter toutes sortes de documents ! Regarder dans les liens cet exemple pour directement aller tirer les données depuis des PDF et ranger les données dans Snowflake. Je crois bien que dbt-core n’y ait pas.
|