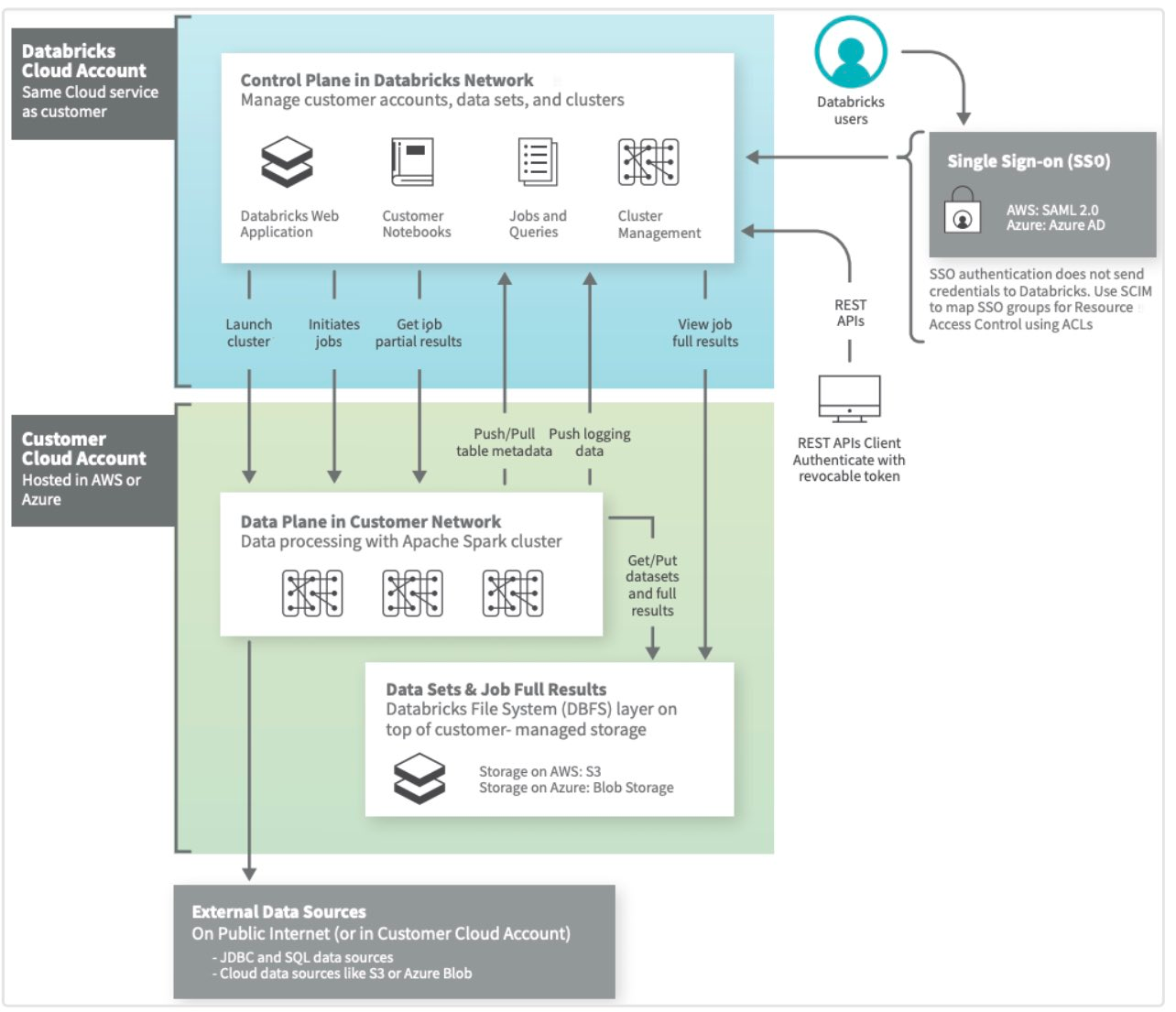
Synaltic travaille sur des projets décisionnels qui durent depuis près de 20 ans ! Ce sont des projets qui sont très riches en matière de patrimoines de données, de flux de traitements, de tableaux de bord. Bien sûr nous employons avec des efforts constants, des plateformes projets (chez nous Redmine). Néanmoins, nos équipes évoluent et bien que la connaissance soit à même notre gestionnaire de projets, elle n’est pas orientée jeux de données ou traitements. Elle ne manifeste pas les liaisons entre données et traitements. Qui plus est, en plus de cataloguer les données de types décisionnels, nous aimerions que toutes les données soient référencées.
Depuis, cette plateforme où toutes nos métadonnées sont centralisées nous voudrions qu’elle nourrisse en retour les métadonnées des systèmes sources. En effet, nous voudrions que ce contexte apporté à la donnée soit directement accessible quelle que soit la manipulation de données que l’on est en train d’opérer, quel que soit le système source y compris dans les solutions de dashboarding ou d’accès aux données.
Pourquoi le streaming est-il si important ? Parce que la vie n’est pas un traitement par lots
Si le cloud, Kubernetes sont de vraies raisons qui poussent les organisations à se moderniser, gérer des traitements de données en temps réel constitue un objectif supplémentaire des DSI. Maintenant que le CDC (Change Data Capture) est à la mode, il s’agit d’orchestrer et d’acheminer les données pour accélérer leur disponibilité vers le système cible et les décisions.
Le modèle de l’open source à l’épreuve du cloud
Toutes les organisations qui ont pour modèle la mutualisation des développements via l’open source ont toutes eu des difficultés à embrasser les cloud. Ce qui est tout autant vrai des grandes solutions propriétaires en SAAS. Cette difficulté est d’autant plus avérée qu’il faut tout le temps tout construire : autorisation, facturation, conformité, vente, etc. Décliner une solution open source en service cloud coûte extrêmement cher. En plus, avec les valeurs de l’open source, il faut que le client garde le contrôle de ses données.
Pour vous lecteurs de cette lettre, il s’agit d’anticiper le changement qui est en train de s’opérer et de saisir certaines complexités que vous devrez résoudre à votre niveau avec l’objectif de conserver vos données et ce aux meilleurs coûts.
Logiciels
Sneller
Sneller est un remplacement transparent et instantané d’Elasticsearch ou d’autres plateformes d’observabilité et de sécurité basées sur SQL, axées sur les données de journaux et d’événements.
Jitsu
Jitsu est un moteur d’ingestion de données entièrement scriptable pour les équipes de données modernes. Configurez un pipeline de données en temps réel en quelques minutes, et non en quelques jours.
Skupper
Skupper, désormais en version 1.0 est une interconnexion de service de couche 7. Il permet une communication sécurisée entre les clusters Kubernetes sans VPN ni règles de pare-feu spéciales. Avec Skupper, votre application peut couvrir plusieurs fournisseurs de cloud, centres de données et régions.