|
Une vive impression d’accélération nous gagne. Une impression d’être empêché de penser. Alors même que de nouvelles tensions internationales cristallisent nos rapports, les avancées de l’IA nous obligent encore et encore à repenser dès à présent notre activité.
Il est utile d’identifier et prendre des mesures face aux impacts à long terme et ce dès à présent. Par contre, il ne faut pas s’y tromper. À court terme, les organisations n’ont pas massivement adopté l’IA, ce qui donne du temps pour s’y préparer.
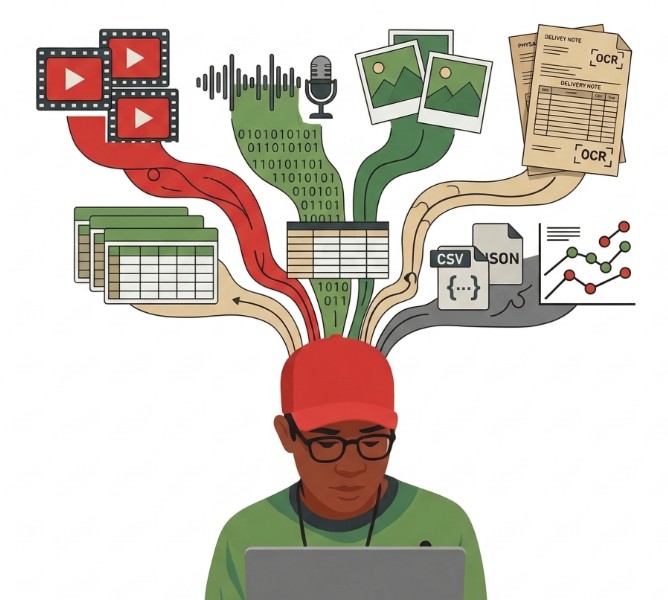
Dans un pareil monde, il va vite être utile de mettre à plat les fondamentaux. La donnée. La valeur ultime que vous tirerez de l’IA consistera à avoir une sorte de “cerveau” de votre organisation. Je ne parle pas des automatisations que vous pouvez d’ores et déjà exploiter. Je parle bien de consolidation de données.
Autrefois, on construisait des data warehouse, même des lakehouses, mais il va maintenant être question de construire des Knowledge Lakehouse. Allez ! Osons des néologismes : “Knowledgehouse”.
Avant que cela n’advienne, la souveraineté est toujours au cœur des préoccupations. Regardons Outre-Rhin, l’État allemand sort une stack large de logiciels open source et libres afin de garantir une souveraineté basée sur des standards. Ce qui est bien avec cette initiative, c’est qu’elle reconnaît cette nécessité de “commun” sur lesquels des entreprises peuvent contribuer et offrir leurs services.
Une telle expertise, couplée à un repositionnement de l’activité, viendra sans doute protéger de l’obsolescence dont les entreprises pourraient elles-mêmes être victimes. Bruno Patino, directeur de la chaîne de télévision ARTE, pose la question dans son dernier livre.
Je ne sais pas ce qu’en pense Yann Le Cun ! Il vient de lever près d’un milliard d’euros afin de proposer des services sur des modèles “world model” qui savent tenir compte du monde physique qui nous entoure.
Nous vous le répétons une fois encore : investissez dans les fondamentaux ! Pour comprendre vos données, vous aurez besoin de leur traçabilité. Le sujet revient dans les solutions de métadonnées dans Apache Iceberg™ avec les premières moutures de la version 3.
|