
L’actualité de la donnée du mois de février 2024 vous parvient et nous nous sommes dits que vous devriez être une petite souris pour découvrir comment nous la construisons et échangeons nos points de vue… Nos discussions sont riches !
Prenez contact avec nous
pour participer vous aussi à cette conversation. Nous serons ravis d’entendre vos points de vue.
Ce mois-ci nos agriculteurs ont bloqués
pour dire qu’eux aussi veulent maîtriser leurs perspectives. Ça paraît fou ; l’agriculteur ne décide pas lui-même de ses prix, ils lui sont imposés ! D’autres ont aussi fait grève ailleurs dans le monde. Pas pour une autre agriculture mais contre l’IA.
Des activistes ont manifesté devant les bureaux de Open AI afin de demander une “pause” !
Le sujet commence à secouer. Vraiment ! Il faut prendre des positions.
La maîtrise de leurs futurs c’est bien ce qu’ont l’intention de faire Microsoft d’une part et Open AI d’autre part. Le premier se lance dans la
construction de sa propre centrale nucléaire
pour alimenter ces data centers. Le deuxième, avec une ambition démesurée, veut maîtriser toute la chaîne de l’IA en commençant
par fabriquer ses propres puces
.

Avez-vous lu Refactoring Database ? Avez-vous lu Agile Analytics ? Avez-vous peur de modifier les schémas de vos tables de base de données ? Avez-vous des craintes à fusionner des champs dans votre MDM ou de votre data warehouse ?
Apache Iceberg offre des réponses. Il transforme vraiment la manière dont vous pouvez gérer et gouverner vos données. Si jusque là vous vous êtes contenté de pousser des données dans S3, sans penser à structurer un minimum : arrêtez tout et adoptez Apache Iceberg !
Reprenez en main la maîtrise de votre chaîne de données. Que se soit en streaming, que ce soit batch, que ce soit pour l’intégration de données, Apache Iceberg devient le compagnon idéal pour vos projets de données.
Vous avez dit quoi, « Modern Data Stack » ? Comment composez-vous la vôtre ? Quelle est la brique d’ingestion ? La brique de stockage ? La brique de gouvernance des données…
C’est ainsi qu’ont évolué nos systèmes d’information.
Arrivez-vous à y voir clair ? Tant mieux parce qu’il va falloir mettre un peu de simplification dans tout ça. Si certains acteurs, eux-mêmes éditeurs, eux-mêmes parties prenantes de la modern data stack s’interrogent, d’autres commencent à dénoncer les montants des factures de certains acteurs devenus tellement incontournables !
Peut-être que vous pourriez, dans un premier temps, optimiser vos coûts sur ces grandes plateformes ? En 2024, c’est le bon moment pour se lancer. Parlons en.
Voilà un mot auquel on ne pouvait s’attendre : #PrivateML
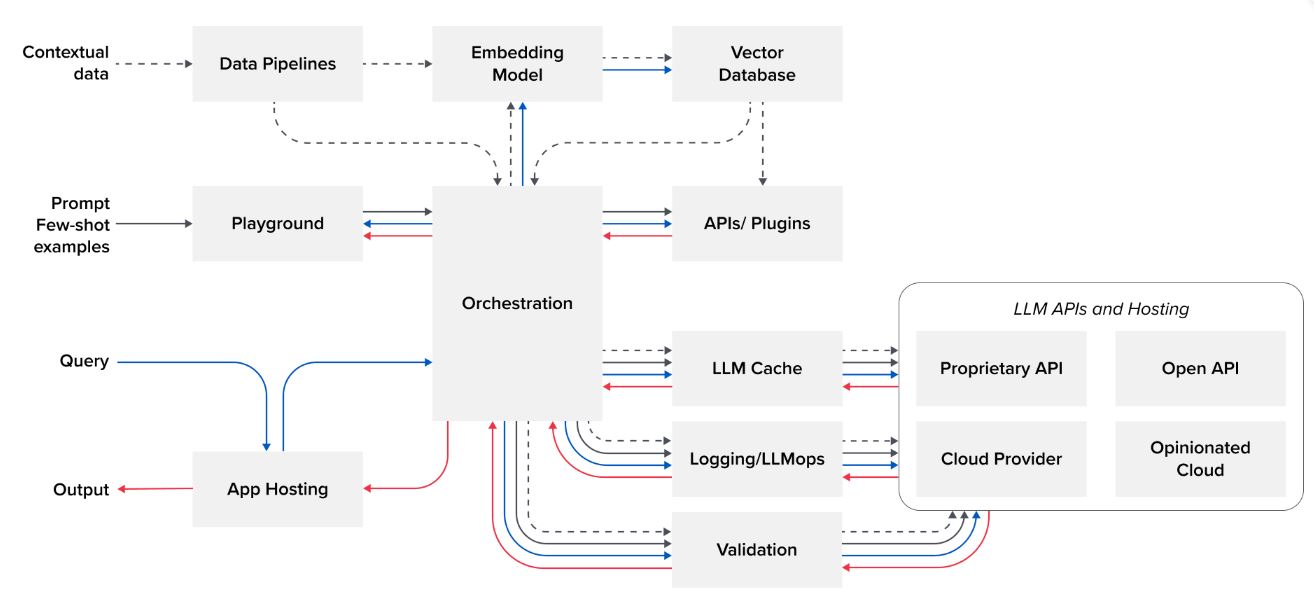
Nombreuses sont les organisations ayant embrassé le cloud. Nombreuses sont les organisations dont les données sont déjà traitées dans le Cloud . Pourtant voilà qu’apparaît le terme “Private ML”.
Les organisations veulent bien de l’IA, mais cette fois-ci, personne n’est dupe : vos données valent de l’or . Pas question que d’autres en profitent, n’est-ce pas ?
Nos clients nous interrogent désormais afin de savoir à quel point nous les accompagnerions sur ces sujets d’IA Generative. Effectivement, des solutions existent pour auto-héberger votre LLM. Et Andreessen-Horowitz nous montre la stack .
La dernière communication de Dremio porte un message percutant : Divisez par 2 vos coûts Snowflake ! Et c’est vrai, remplacer Snowflake par Dremio peut permettre de diminuer drastiquement les coûts, notamment vis à vis du stockage des réplications, du cache et des extractions temporaires … qui n’ont alors plus lieu d’être !
Cependant, ce n’est pas du tout l’approche que nous avons à Synaltic.
Nous ne remettons pas en question les investissements déjà réalisés,
nous suggérons de compléter les architectures existantes par Dremio pour limiter et mieux maîtriser les coûts du Data Lake déjà en place.
Il s’agit donc d’utiliser Dremio pour éviter la recopie de données, faciliter le Self Service et mettre en place des accélérations là où l’existant peine parfois.