
Ce mois-ci nous avons eu l’opportunité de participer à la conférence OW2 Con’ 24 ! Toute la communauté open source européenne était réunie pour deux jours de conférences intenses. De très belles rencontres. Nous y avons surtout promu Apache Iceberg et son facilitateur Dremio ! Eux aussi sont développés en open source et participent clairement à rendre les systèmes d’information plus interopérables, plus ouverts afin de construire la souveraineté par les données !
Plus personne ne remettra en cause la recherche de la maîtrise et du contrôle de son patrimoine de données quand même un Snowflake peut se laisser dérober des centaines de millions de lignes de données de ses clients…
Nous revenons souvent sur la souveraineté dans cette lettre. Conserver sa liberté ! Conserver la maîtrise de son destin, n’est-ce pas important ?
Tariq KRIM nous invite à revivre 40 ans de Géopolitique Numérique. Pendant ce temps-là on mesure déjà comment l’IA générative employée par des forces obscures fait mal à la démocratie .
Pour conclure cette introduction, un mot d’ordre : 👉 Gardez le contrôle de vos données !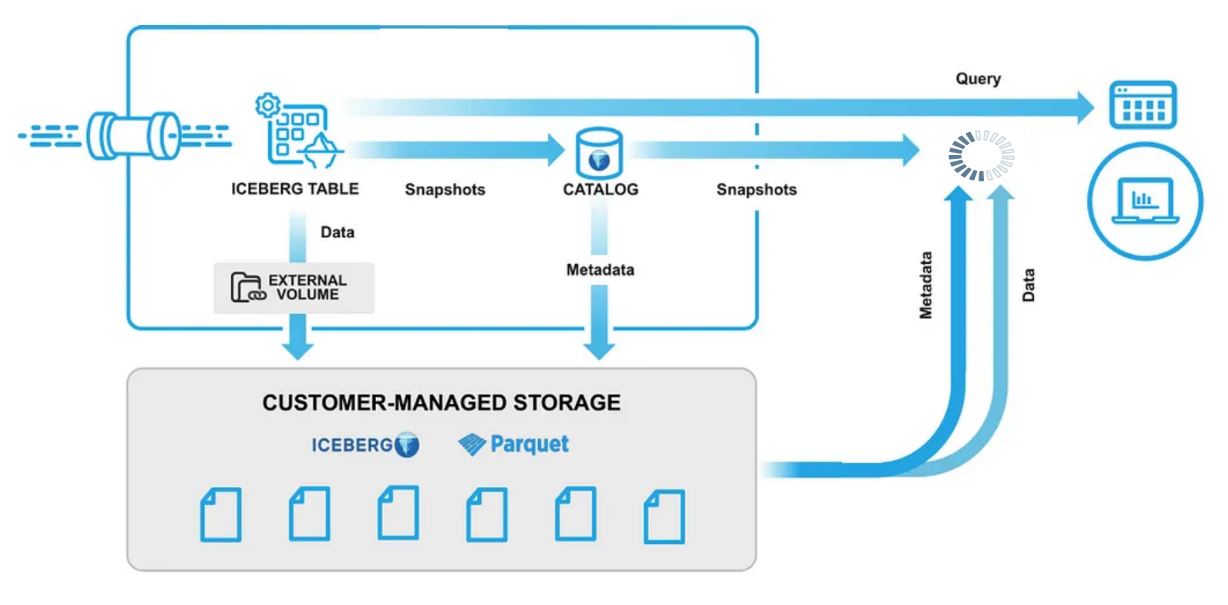
Le data warehouse est mort ! Vive le data lakehouse ! Les annonces des dernières semaines ont transformé pour toujours le marché de la donnée !
Ne construisez plus de data warehouse mais bien des data lakehouse. De la sorte, vous en profiterez pour arrêter de partager des fichiers de données , et partagerez des données directement. Plus de CSV !
Et en terme de gestion de l’évolution de vos schémas… C’est ici que dans l’architecture du data lakehouse qu’intervient le “catalogue” ! Oui, le format Apache Iceberg a gagné ! Cependant il a aussi amené une vision totalement renouvelée du catalogue de données, qui devenu interopérable offre la possibilité de cesser de copier, et copier, et encore copier la donnée pour tout compte fait simplement y accéder depuis les environnements analytiques ! Le catalogue n’a pas fini de faire parler de lui !
Par ailleurs, les éditeurs SAAS feraient bien d’adopter Apache Iceberg et son catalogue ! Ce serait tellement mieux que d’employer des APIs , et de les appeller un à un pour reconstituer des données dans le cadre d’export massif de données.
Travailler avec les données est à la jonction de nombre des connaissances, de savoir faire, de méthodes et pratiques informatiques. Dans le cadre de projets de données, les métiers n’ont pas forcément toutes ces connaissances. Il convient de les leur apporter afin que les projets de données atteignent réellement leurs objectifs.
Carrefour détaille l’organisation de ses équipes autour des données. Elles ont en leur sein non pas un Data Facilitateur mais un Data Translator. Il s’agit au quotidien de faire converger besoins métiers et usage des données.
De plus en plus d’acteurs partagent le voyage autour de leur données. Ici encore Blablacar…
Et vous, voudriez vous nous partager votre expérience ? Nous serions ravis de vous écouter et d’échanger autour de l’état de l’art.
Toutes les organisations partagent des données. Leur appropriation est d’autant plus simple que leur structuration est intelligible pour les utilisateurs qui s’en servent. Il y a de nombreuses structurations possibles
: le modèle transactionnel, la troisième forme normale sont plus appropriés aux systèmes opérationnels.
Pour ce qui est du décisionnel, il existe le modèle en étoile, le modèle en flocon, data vault (2.0)… Plus récemment on a vu apparaître One Big Table . Sans doute trop peu de personnes mettent en avant Activity Schema . Bien sûr, chacune de ces modélisations présente avantages et inconvénients. Faites bien votre choix.
Aussi, ces modélisations peuvent être retrouvées couplées à une représentation de la donnée organisée sous forme de couches sémantiques
.
Par prudence, il est opportun de miser sur des approches modernes quant à la mise en œuvre de vos modélisations à même votre data warehouse ou data lakehouse. SqlMesh est en train de changer l’approche…
LOGICIELS
Talend a rejoint Qlik ! Alors le studio prend les couleurs de Qlik et se refait une nouvelle jeunesse. Les portails Talend sont aussi passés aux couleurs et services Qlik, que ce soit le portail communautaire ou le portail de support professionnel. Pensez à vous créez un nouveau compte !
L’offre de Jetic est très séduisante et productive ! La communauté Apache Camel avance une nouvelle version de son studio Kaoto désormais en version v2.0.
Thibaut Gourdel, ex-Talend, s’est lancé dans le développement d’un ETL open source générant du Python. Disponible depuis peu, la version MVP dispose d’un ensemble de connecteurs permettant de développer des pipelines en mode graphique / lowcode et générer du code python prêt à être exécuté.