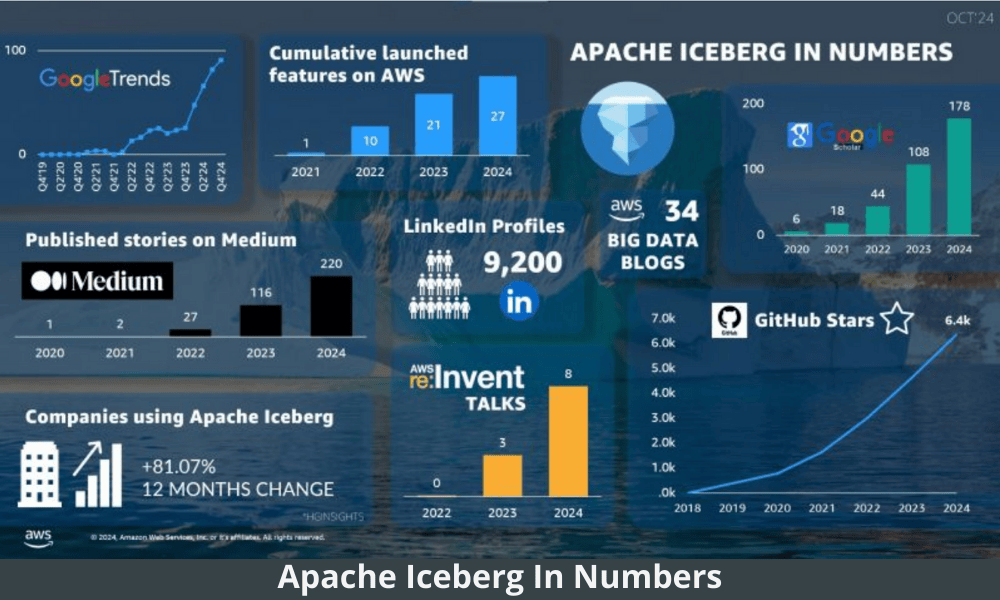
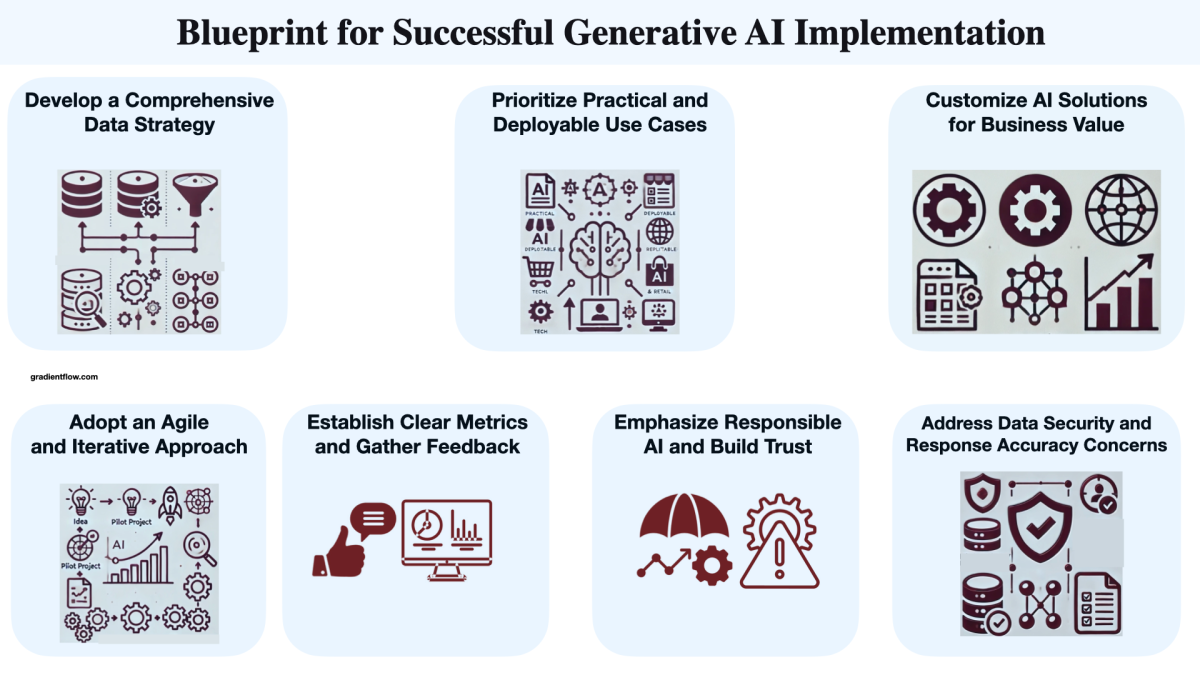
Ce monde nous rend fou ! Oui, il nous rend fou parce que d’un côté on veut aller sur Mars en respectant la physique, de l’autre on raconte n’importe quoi défiant ces mêmes lois de la physique ! 20 ans de Synaltic ! 20 ans de gestion de données, 20 ans à promouvoir les valeurs de l’open source et aujourd’hui plus que jamais nous invitons les organisations à garder le contrôle de leurs données. 20 ans que l’on se bat pour que les organisations forment, montent en compétence sur l’appropriation des données ! Il faut de l’intuition ! Il faut prendre des risques, il faut aussi des paris. Cependant la physique existe ! La qualité des données est cruciale. Savoir à quoi sert un indicateur. Savoir comment il est calculé. Décider avec cet indicateur… Y compris en prenant des risques et en suivant son intuition… Mais au moins on décide en connaissance de cause. Tout ceci pour vous dire qu’il faut chausser les bonnes lunettes ! C’est peut-être ce que nous invite à faire notre Président en devenant des “carnivores”. Non des « au moins omnivores » ! Face à la situation où nous sommes, il est sûr que nous aurons besoin d’innovation étant donné la corde raide sur laquelle nous avançons actuellement ! Innover c’est sans doute savoir s’exécuter chez de plus gros acteurs comme Snowflake et Databricks – devenus incontournables. Innover c’est sans doute porter son cadre de programmation au sein de SQL alors que l’on avait jusque-là décrier le moteur et le langage.
|