
L’actualité est très lourde n’est-ce pas ? Heureusement que l’on a Apache Iceberg. Il continue d’inciter à l’innovation. Imaginer un monde où toutes vos données y compris celles stockées dans vos bases de données opérationnelles soit directement accessibles via
Apache Iceberg Rest Catalog
!
Bien sûr
tout le monde ne parle que d’IA
! Même notre président. J’aime à répéter que j’adore l’IA générative ! Au moins tout le monde a subitement pris conscience de l’importance de la donnée. Tout le monde a plus que jamais intégré ce que peut être la
“valorisation” des données.
Tout le monde a aussi compris pourquoi
la qualité des données
est d’une importance capitale ! Autrement, vos décisions comportent quelques hallucinations…
Prenez soin de vos données :
construisez vos plateformes de données avec des formats ouverts
.
Ho ! Le feuilleton Databricks face à Snowflake continue ! Ne les opposez pas ! Apache Iceberg vous permet de garder le contrôle de vos données : vous pouvez choisir le moteur qui vous convient en fonction du traitement ou du type de traitement que vous avez à réaliser !
Et ça c’est grâce à l’open source.
Ah ! Tout le monde ne comprend pas le concept d’open source, de construction mutualisée, de construction de standards ou de communs !
A tel point que Microsoft a libéré deux solutions open source ce mois-ci !
Et nous on a Luc Ferry !
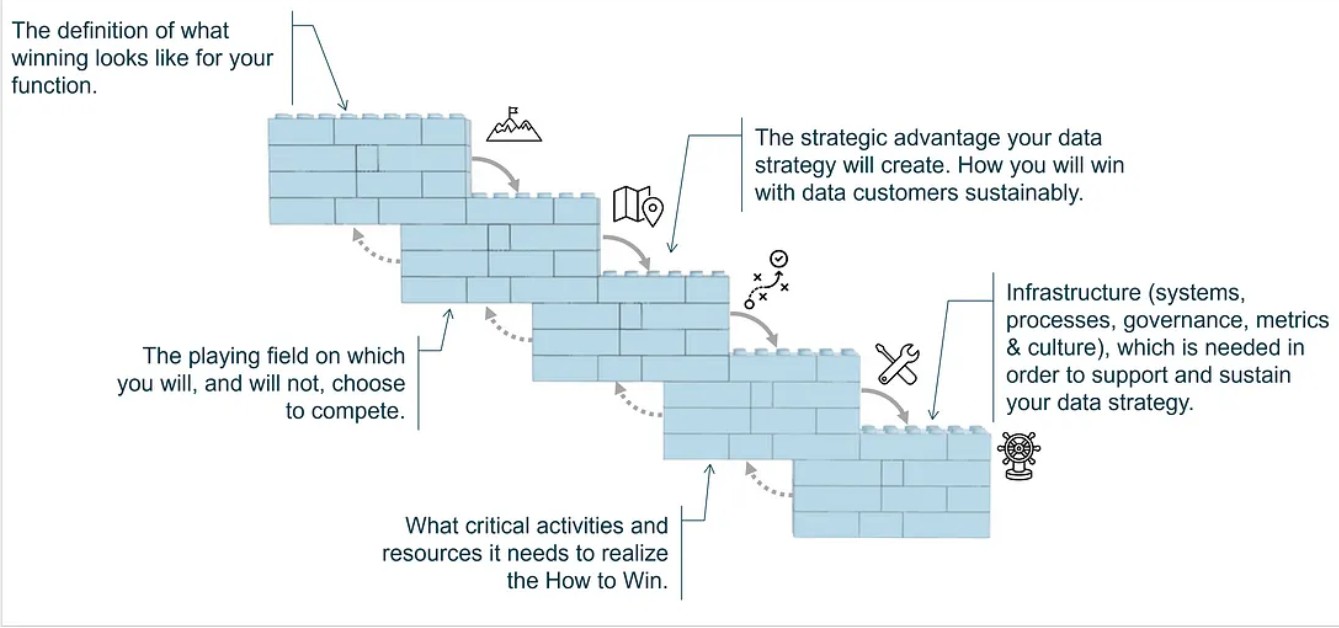
Faut-il une culture de la donnée avant d’avoir une stratégie qui s’appuie sur les données ? La poule était-elle là avant l’œuf ?
Mettre en place une plateforme de données est certainement plus simple que beaucoup ne le pensent. Tout le monde utilise déjà de la donnée ! Toutes les organisations exploitent le tableur depuis tellement longtemps.
Plutôt que de chercher à renverser la table et bousculer comme d’habitude avec des approches top-down… Peut-être devrait-on faire confiance à ce petit groupe qui semble avoir une réelle conscience des enjeux.
On peut certainement les accompagner au fur et à mesure, transformer leur rôle par l’apport de connaissances, l’apport d’outils pour que leur groupe deviennent des communautés grâce à leur travail de data facilitateur, de concierge des données, dit autrement de Data Steward ! Le reste viendra !
Si effectivement, les utilisateurs qui ont le “Mindset” sauront se mouvoir vers ce nouveau rôle, il en demeure pas moins qu’il est utile que chaque organisation ait intégré – vraiment – comment la donnée va l’aider à “repenser” sa stratégie. Il faut des directeurs techniques, des CTO dans les directions, dans les conseils d’administration.
Certaines organisations laissent
le sentiment qu’elles ont toujours fait sans
et que “business as usual” : “
On ne comprend pas pourquoi on en a besoin. On est une organisation établie. On fait un chiffre conséquent. On a gagné quelques clients de plus… Tout va bien. N’est-ce pas ? »
Mince ! On avait omis la démographie de l’organisation !
La donnée sert les décisions, elle ne les remplace pas. Mais peut-on réellement faire sans ?

Il est certaines pratiques qui coulent du bon sens ! Je suis issu de cette époque du “ in database ”, alors le “ in data lakehouse ” je le comprends bien. Je viens aussi de cette époque où l’on ne confiait à un rapport que l’affichage ! Zéro calcul dans le rapport ! J’ai vu aussi des organisations employer un système de reporting comme ETL ! Mais quelle folie !
“Shift Left” :
penser la qualité, la gouvernance au plus tôt dans le processus
! C’est-à-dire au plus près de la source. Cela relève du bon sens ! N’est-ce pas ?
Pratiquez-vous le “Shift Left” dans la mise en œuvre de vos tableaux de bord Tableau, PowerBI ? Et Apache Superset vous le connaissez celui-là ?
Le shift left c’est aussi à une plus large échelle. A l’heure de l’IA et de la capacité des organisations à employer leur patrimoine des données pour mieux la nourrir, gouverner la donnée, une donnée de qualité c’est stratégique ! Pas besoin de tout inventer ou réinventer.
OpenAI nous a propulsé dans l’IA dite générative et tente d’approcher l’IA dite généralisée ! Beaucoup d’entre nous emploi désormais ces agents conventionnels, ces assistants pour reformuler ce qu’ils ont coûteusement ingurgité.
Si bien que l’on peut souvent avoir cette question quant à l’utilité de ces outils… Bien sûr qu’il est des domaines où ils démontrent définitivement leur apport au “bon” fonctionnement de la société. C’est ce que Terra Nova a compilé. Mais il faut bien se rendre compte qu’à la manière de GNU Linux ou du Web, l’IA va être présente dans nombre de processus et ce sans jamais se présenter .
Dremio a introduit des “Autonomous Reflection”, une gestion intelligente, sans intervention humaine, d’un mécanisme de mise en cache des données pour les délivrer plus rapidement. Oracle a déjà “Autonomous Database” !
Et que dire de la construction de planning avec des contraintes très fortes de disponibilité ou des prises de congés… Ne faut-il pas un peu d’IA pour gagner du temps dans leur élaboration ? Timefold c’est un fork d’OptaPlanner ! Oui pour gérer des plannings ou de l’aiguillage complexe ! Et bien oui avec l’IA, Timefold va bien plus loin .
À DÉCOUVRIR
RAGformation est un outil open-source qui automatise la sélection de services cloud, l’estimation des coûts et la conception d’architectures en fonction des besoins spécifiques des utilisateurs. En entrant une description en langage naturel, les utilisateurs reçoivent un diagramme de flux représentant les services cloud recommandés, accompagné d’une estimation détaillée des coûts.
L’outil permet également d’affiner les recommandations en fonction des préférences ou des contraintes budgétaires, et génère un rapport complet une fois la configuration optimale validée. Ce projet a remporté le « Box Award » lors du LlamaIndex hackathon.
LOGICIELS
Datahub le catalog de données pour les entreprises passe sa version 1.0. Pour fêter ça une fonctionnalité de taille ! Être aussi un catalogue Apache Iceberg !
DataHub 1.0 Launches, Celebrating Five Years of Open Source Innovation