Voilà bientôt 20 ans que le mathématicien britannique, M. Clive Humby, citait pour la première fois « Data is the new oil » ! Avec toutes ces années de recul, avec l’avènement des LLMs, il est clair pour tout le monde que les données sont le moteur de notre économie moderne. Ce qui nous ramène à un élément vital et essentiel d’un tel système : l’échange des données. Toute cette machinerie est soutenue par ces échanges de données. Tout ! Oui ! Nous avons les API, c’est vrai, cependant nous nous avons surtout des échanges plus massifs (pensez par exemple au monde de l’assurance, au monde des transports, à l’e-commerce…).
Dans le métier qui est le nôtre, secteur de l’ESN, nous exploitons beaucoup la notion de « projets », les dates, les jalons, l’échéance… Pourtant, nous sommes bien des cordonniers mal chaussés ! Nous n’avons pas de standard qui facilite les échanges de données de gestion de projets ! La belle affaire ! Alors ces jours-ci, j’ai salué l’initiative de Plane un nouvel éditeur dans la gestion de projet ! Il propose OWL, un cadre qui facilitera l’échange de données entre les plateformes de gestion de projet. Fini le verrouillage fournisseur ?
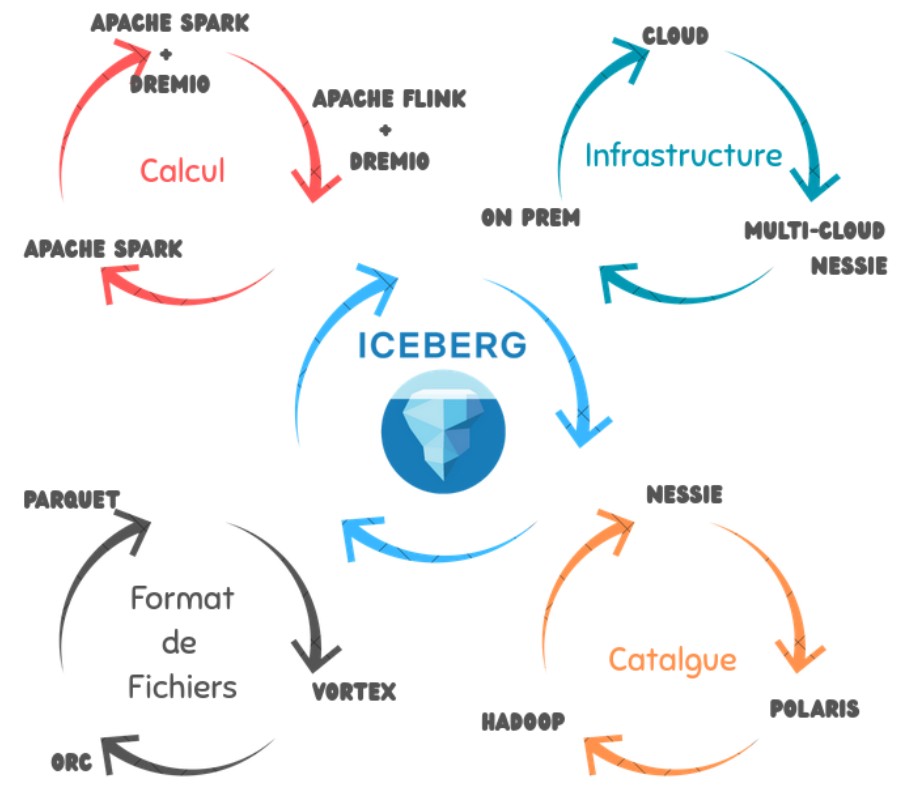
Saluons aussi l’interview du Président de Databricks, Ali Ghodsi, qui plaide et indique que l’industrie aurait trouvé son format universel pour les données ! Et vous savez lequel est-ce ? Apache Iceberg !
Des annonces nous en avons eu plein ! Aussi bien chez Snowflake que chez Databricks. Comme ils font, en ce moment, la pluie et le beau temps sur ce marché, on prête l’oreille… On me dit que ce ne sont que des annonces… et qu’il va falloir attendre un peu pour que les choses prennent forme plus concrètement.
Dremio n’est pas en reste car il fait savoir que sa plateforme pour la gestion de Lakehouse sait faire aussi bien que les autres, voire fait mieux… beaucoup mieux même.
|