
Analytic Engineering
Synaltic vous propose principalement des ingénieurs des données, et nous vous avons récemment introduit le Data Facilitateur – celui-ci vous accompagne à faire progresser la culture de la donnée – aujourd’hui, il est désormais utile que nous parlions du Analytic Engineer !

C’est celui qui vous mettra à disposition vos datasets et qui prendra soin à l’heure où tout se passe dans les cloud Data Warehouse ou les Lakehouse. Et à l’heure de Dremio !
Operational Analytic
Les architectures de streaming ont apporté une nouvelle manière de voir l’intégration de données ; elles accélèrent la mise à disposition des données ! J’aime à dire que ce sont les données des processus des organisations qui y transitent ; alors pourquoi ne pas les analyser pendant qu’elles sont acheminées vers leur destination en temps réel ?
Les organisations ont longtemps exporté les données de leurs solutions de gestion pour en comprendre leurs activités quotidiennes… Certes, la consolidation des données existe au travers des data warehouse, des data lake… Mais il est bien vrai que les utilisateurs ont besoin de décision au plus près de leurs solutions.
Une informatique décisionnelle temps réel a longtemps été vue comme un produit de luxe… Mais KSQL, Materialize, Flink… offrent des réponses nouvelles. Les formats de données aussi changent la donne, c’est le cas d’Apache Arrow : un format de données en colonne et en mémoire maintenant largement adopté. Et j’allais oublier celui sans qui cette vision ne peut se réaliser : Debezium… Fini le change data capture old school, maintenant, c’est léger et sans altérer les performances de vos sources…
L’utilisation massive des données, fait qu’elle est entre toutes les mains. Les data warehouse, les analyses qui en sont issues, par exemple sous forme de tableaux de bord ne suffisent plus ; il est souvent nécessaire d’enrichir les données opérationnelles à partir d’agrégations ou d’indicateurs constitués dans les systèmes analytiques ! C’est une pratique observée qui fait naître un type de processus que l’on nomme désormais de “Reverse ETL”.
Les organisations ont longtemps exporté les données de leurs solutions de gestion pour en comprendre leurs activités quotidiennes… Certes, la consolidation des données existe au travers des data warehouse, des data lake… Mais il est bien vrai que les utilisateurs ont besoin de décision au plus près de leurs solutions.
Une informatique décisionnelle temps réel a longtemps été vue comme un produit de luxe… Mais KSQL, Materialize, Flink… offrent des réponses nouvelles. Les formats de données aussi changent la donne, c’est le cas d’Apache Arrow : un format de données en colonne et en mémoire maintenant largement adopté. Et j’allais oublier celui sans qui cette vision ne peut se réaliser : Debezium… Fini le change data capture old school, maintenant, c’est léger et sans altérer les performances de vos sources…
L’utilisation massive des données, fait qu’elle est entre toutes les mains. Les data warehouse, les analyses qui en sont issues, par exemple sous forme de tableaux de bord ne suffisent plus ; il est souvent nécessaire d’enrichir les données opérationnelles à partir d’agrégations ou d’indicateurs constitués dans les systèmes analytiques ! C’est une pratique observée qui fait naître un type de processus que l’on nomme désormais de “Reverse ETL”.
Architecture légère pour l’analytique
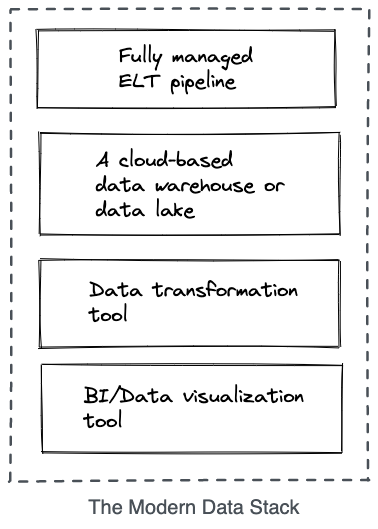
Dans ces colonnes, nous vous avons déjà parlé d’Airbyte ! Un ETL qui revisite la discipline : le cœur c’est l’ingestion ! Parce que le rôle premier de ces ETL là est simplement d’acheminer la donnée vers l’endroit où la donnée va être travaillée et enrichie. C’est par exemple le cas au sein d’un data warehouse et d’un data lake(house).
Les outils pour transformer cette donnée entrent alors en scène (dbt, dataform) afin de la modeler et qu’elle puisse être consommée directement par les outils de Business Intelligence voir les exposer sous forme d’API ou les ré-injecter dans des systèmes source (reverse ETL).
A une autre époque, on parlait de “IN Database« , maintenant on va dire “Native Data Warehouse”...
Les outils pour transformer cette donnée entrent alors en scène (dbt, dataform) afin de la modeler et qu’elle puisse être consommée directement par les outils de Business Intelligence voir les exposer sous forme d’API ou les ré-injecter dans des systèmes source (reverse ETL).
A une autre époque, on parlait de “IN Database« , maintenant on va dire “Native Data Warehouse”...